Research Summary
With a focus on identifying and applying relevant historical information to new situations, the predominant view of health informatics today is that of a black box. One swapping in and out the latest statistical and computational techniques to model the extensive scale, scope, and variety of digital health and wellness information now available. Drawing on the collective experiences of millions of practitioners, patients, and researchers, these models have been successful in driving forward personalized and precision health initiatives; performing a myriad of predictive and analytical tasks with an efficiency or accuracy individuals can no longer parallel. However, with a focus on application to future situations, it is often overlooked how informatics techniques can evaluate and formulate data not only explain what is observed, but to advance and inform new knowledge.
My research works to address exactly this, establishing how the techniques of health informatics can aid practitioners and researchers in utilizing the extensive set of data now digitally available to understand, analyze, evaluate and synthesize new information around the practice and administration of healthcare. To do so, my work has primarily centered around three overarching themes. First, demonstrating how informatics techniques can be employed to understand data and highlight opportunities to improve research, operations, and care within the healthcare system. Second, exploring how informatics can uncover relations not readily evident without computational aid. Finally, illustrating how informatics can be utilized to formulate new understanding and advance current perceptions about health practice and data we collect from it.
At the core of my work lies the notion of augmentation, not automation. Working closely with clinicians and practitioners I am interested in answering questions and developing tools which enhance the effectiveness of those actively engaged in the healthcare system, augmenting their existing knowledge rather than replacing the individual. I have a specific interest in neonatal and pediatric research, looking to the ways in which informatics can improve the quality and effectiveness of care. In particular, within intensive care settings, where despite extensive monitoring and documentation a significant portion of the recorded information remains underutilized.
Interests
- Health Informatics
- Neonatal and Pediatric Research
- Population Health
- Data Science
- Machine Learning
- Statistical Methods
- Big Data
Research Projects
-

Providing care for premature, low birth-weight, or otherwise ill newborn infants, the neonatal intensive care unit (NICU) offers treatment for a wide array of conditions and needs. Although, due to the highly volatile state of the infants admitted to the NICU, the care patterns associated with their treatment are often highly complex; as evidence-based medicine becomes an increasingly central aspect of healthcare, the ability to draw insights and highlight best practices from these patterns represents an important step in improving the quality and effectiveness of infant care. As infants in the NICU are continually monitored throughout their admission, many since the time of their birth, I am deeply interested in the application of informatics techniques to extract such insights from the rich set of heterogeneous clinical and operational neonatal data collected for each patient.
As such, I have focused several works on the analysis of NICU data encompassing common clinical elements such as diagnoses, procedures, and medications, the use of specialized environmental technologies such as isolettes and ultraviolet light, parental interactions, various forms of respiratory support, and the complex network of different clinicians offering such care. Studying a range of topics including how maternal stress is affected by the nursing structure and network providing care to extremely preterm infants, and how care structures of extremely ill infants relate to their neurodevelopmental scores at age two. Most recently establishing associations between congenital heart disease and incidence of parenteral nutrition–associated liver disease.
Related Publications:
- Feldman, Keith, Christopher R. Nitkin, Alain Cuna, Alexandra Oschman, William E. Truog, Michael Norberg, Michael Nyp, Jane B. Taylor, and Tamorah Lewis. "Corticosteroid response predicts bronchopulmonary dysplasia status at 36 weeks in preterm infants treated with dexamethasone: A pilot study." Pediatric Pulmonology (2022).
- Santharam, Yasasvhinie, Christopher R. Nitkin, Ayan Rajgarhia, Alexandra Oschman, Brian Lee, Ryan Fischer, and Feldman, K.. Association between congenital heart disease and parenteral nutrition–associated liver disease in neonates: A retrospective cohort study. Journal of Parenteral and Enteral Nutrition (2023).
- Gonya, Jenn, Feldman, Keith, and Nitesh V. Chawla. “Nursing Networks in the NICU and Their Association with Maternal Stress: A Pilot Study” Journal of Nursing Management (2018).
- Feldman, Keith, and Nitesh V. Chawla. “Admission Duration Model for Infant Treatment (ADMIT),” IEEE International Conference on Bioinformatics and Biomedicine (2014).
-
Particularly within the human-centric field of health, the ability to understand the context and characteristics of information remains an integral aspect of the ability to learn about the processes that generate information and the ways in which it can be most effectively used. As such, I am interested in exploring the ability of informatics techniques to uncover latent characteristics of health data and the implications to research and practice that may arise from an awareness of such attributes.
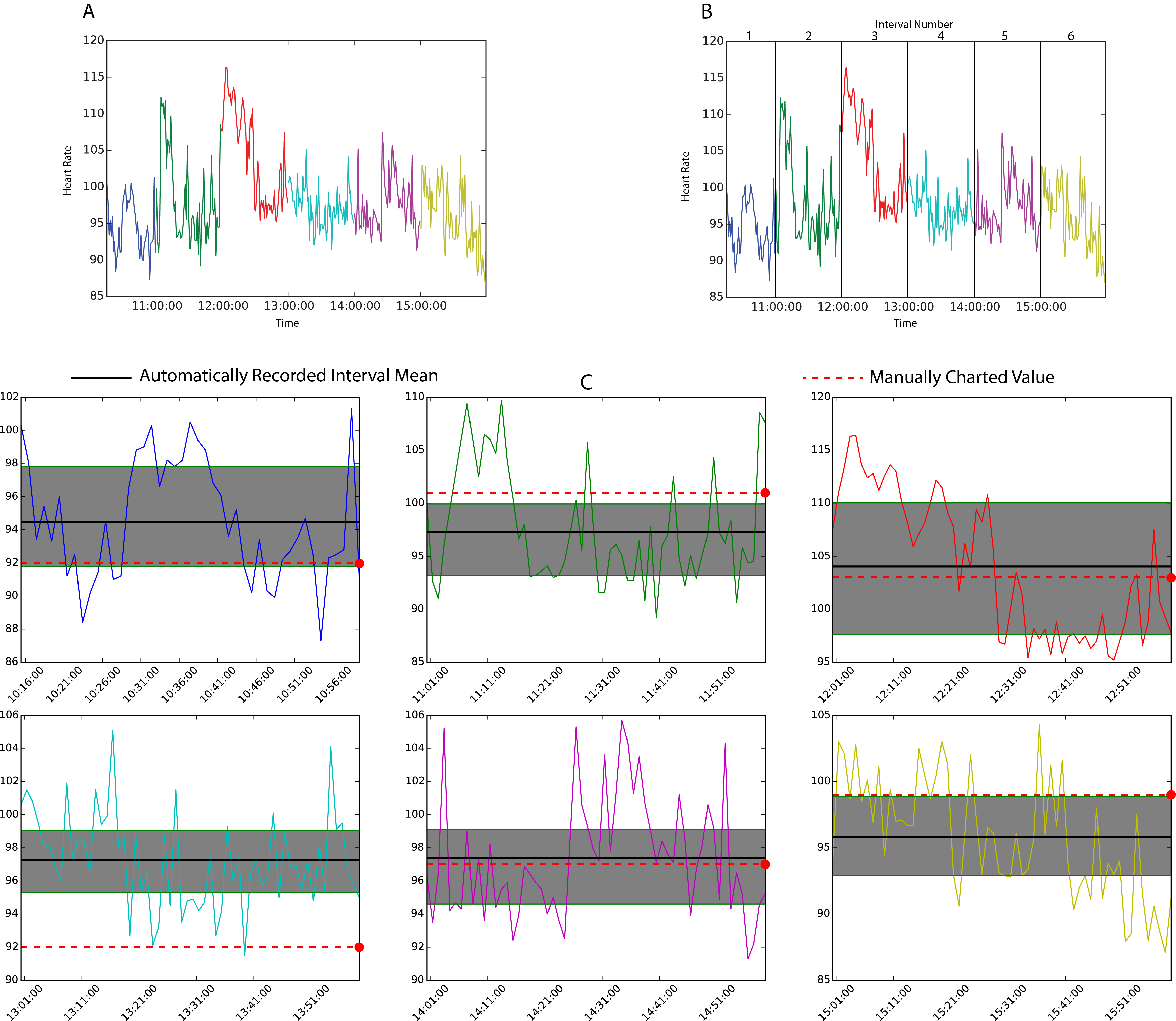
My work in this area has focused on both the manner in which data is created or collected, Highlighting fundamental structural, linguistic, and topical differences among clinical text written by clinicians with varying job roles and more recently, establishing significant differences in variability between vital signs recorded in a patient’s chart and those recorded from bedside monitors, discussing the importance of accurately capturing such variability for a number of clinical applications. It has also demonstrated how computational techniques can be used to uncover and leverage latent characteristics of healthcare data. Examples include developing frameworks to determine survey question subjects best able to measure intervention need, and identifying combinational effects of psychological factors on childhood obesity intervention success.
Related Publication:
- Feldman, Keith, Annie J. Rohan, and Nitesh V. Chawla. "Discrete Heart Rate Values or Continuous Streams? Representation, Variability, and Meaningful Use of Vital Sign Data." CIN: Computers, Informatics, Nursing (2021).
- Feldman, Keith, Gisela MB Solymos, Maria Paula de Albuquerque, and Nitesh V. Chawla. "Unraveling complexity about childhood obesity and nutritional interventions: Modeling interactions Among psychological factors." Scientific Reports (2019).
- Feldman, Keith, Spyros Kotoulas, and Nitesh V. Chawla. “TIQS: Targeted Iterative Question Selection for Health Interventions.” Journal of Healthcare Informatics Research (2018)
- Feldman, Keith, Nicholas Hazekamp, and Nitesh V. Chawla. "Mining the Clinical Narrative: All Text Are Not Equal." IEEE International Conference on Healthcare Informatics (2016).
-
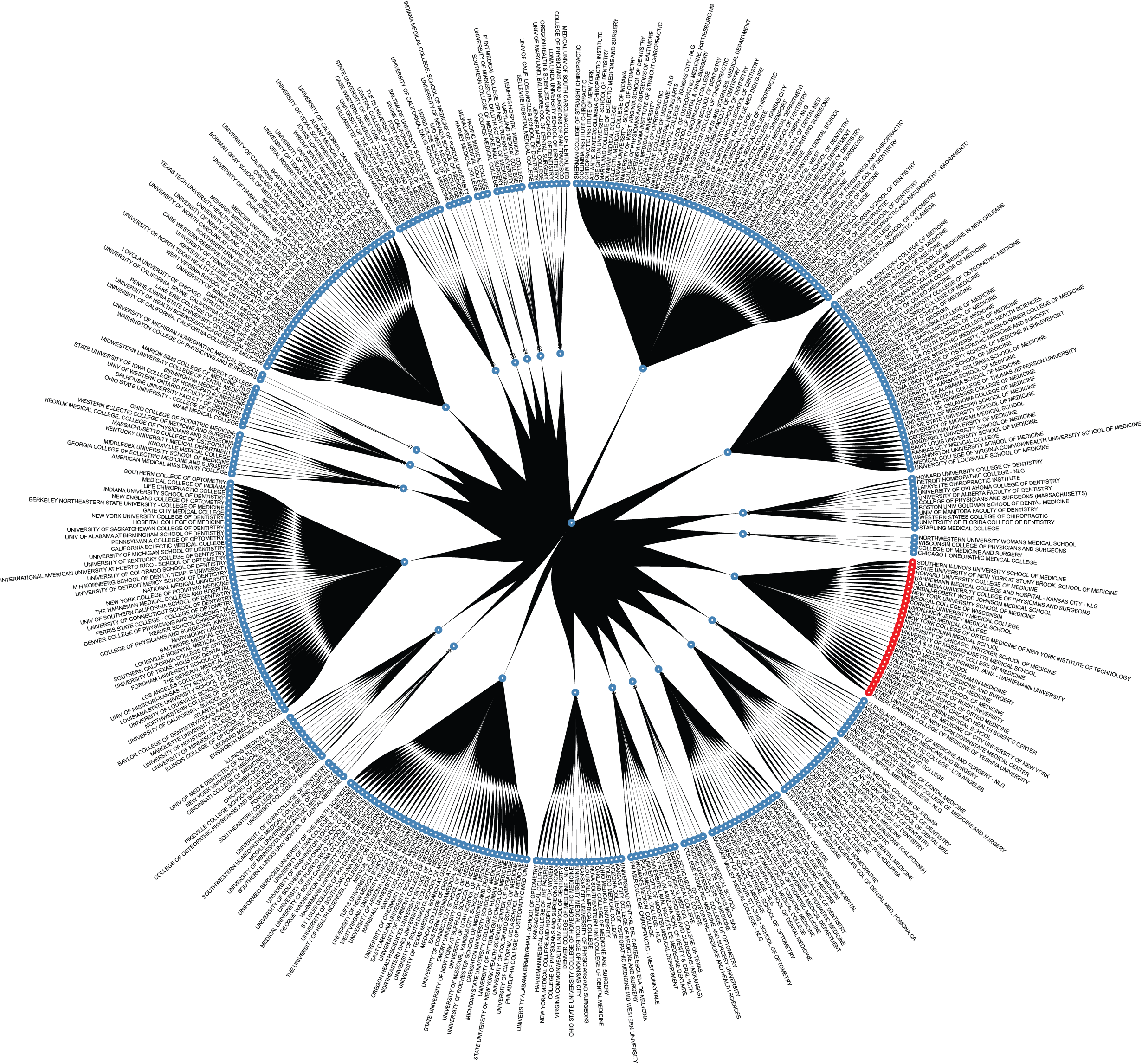
No longer constrained by the need to physically aggregate information, the ability to collect digital health and wellness data from individuals around the globe has provided researchers an opportunity to study healthcare and its practice across a vast array of clinical profiles, socio-economic conditions, and geographic locations. However, the scale at which this information has become available represents only one aspect of how informatics techniques can facilitate the study of health within a clinical or geographic population. Today the ability to collect, infer, and analyze information collected from numerous indirect sources has advanced our notion of health by allowing for the study of factors around an individual’s life and work, better known as their socio-ecological model. Ranging from government curated metrics to community-level economic and industrial profiles, I am particularly interested in how we can combine such population level data with individual level clinical factors to improve our understanding of health and healthcare outcomes.
My research in this area has focused on both the scale and diversity of population health data. In doing so my early work introduced a novel network graph-based approach to identify a diagnosis. While more recent works have taken a broader view, aggregating government curated datasets with public information to uncover novel associations between the medical school attended and a physician’s procedure choices and pricing. Later work focused better elucidating clinical factors underlying colloquial phenomena such as “weekend effects”
Related Publication:
- Markley, Catherine, Keith Feldman, and Nitesh V. Chawla. “Outside the Hospital Walls: Associations of Value Based Care Metrics and Community Health Factors”, IEEE International Conference on Biomedical and Health Informatics (2019).
- Feldman, Keith, and Nitesh V. Chawla. "Does Medical School Training Relate to Practice? Evidence from Big Data." Big data (2015).
- Faust, Louis*, Keith Feldman*, Nitesh V. Chawla. " Examining the Weekend Effect Across ICU Performance Metrics." BMC Critical Care (2019).
- Feldman, Keith, Gregor Stiglic, Dipanwita Dasgupta, Mark Kricheff, Zoran Obradovic, and Nitesh V. Chawla. "Insights into Population Health Management Through Disease Diagnoses Networks." Scientific Reports 6 (2016).
-
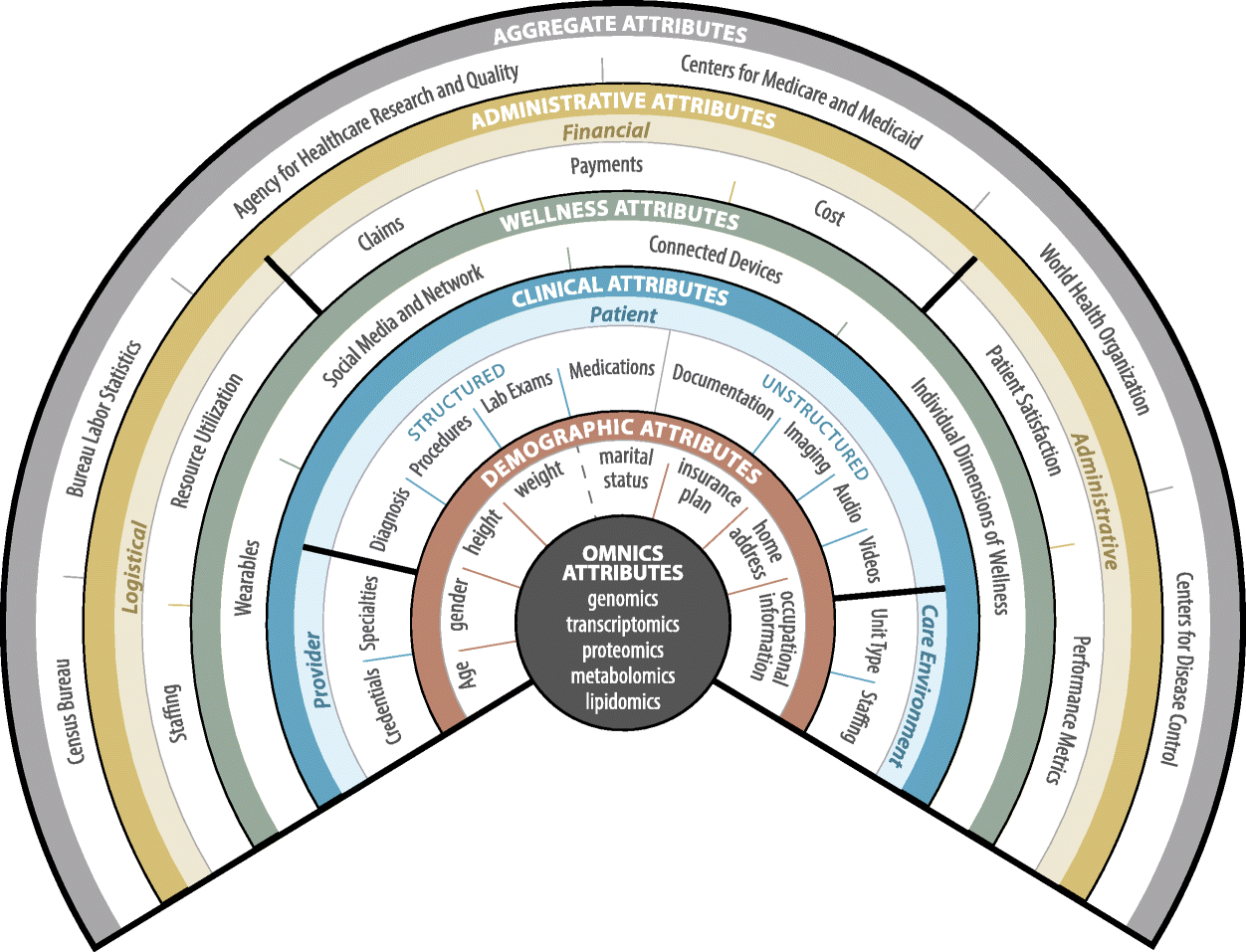
As health and wellness data continues to be generated at unprecedented volume, at high velocity, and from a variety of sources of questionable veracity, it has become clear the ability to simply execute informatics techniques is not yet enough to ensure their effective use. Beyond the ability to perform technically correct operations, the successful utilization of informatics techniques to extract meaningful insights requires a careful consideration of the processes by which the data is obtained, the technical underpinnings of the techniques utilized for analysis, and the manner in which the insights are intended to be utilized. Accordingly, I am interested in research that explores the impact of these factors on the aspects of performance and interpretability that form an integral aspect of the connection between the healthcare system and the statistical methodologies of informatics.
Such work has included a study exploring the impact of healthcare’s heterogeneous, high dimensional, probabilistic, incomplete, uncertain, and noisy data on the ability to preprocess, execute, and interpret informatics’ models. A case study into a disease prediction algorithm, highlighting how both the diseases being predicted and the demographics of those individuals being analyzed can have an impact on the model’s performance, and how awareness of such latent predispositions can be useful to practitioners who will be the primary consumers of such output. Most recently highlighting how the integration of wearable and EMR data can be utilized to accomplish multiple tasks, including identifying who would most benefit from passive AFib monitoring.
Related Publication:
- Feldman, Keith, Ray G. Duncan, An Nguyen, Galen Cook-Wiens, Yaron Elad, Teryl Nuckols, and Joshua M. Pevnick. "Will Apple devices’ passive atrial fibrillation detection prevent strokes? Estimating the proportion of high-risk actionable patients with real-world user data." JAMIA (2022).
- Feldman, Keith, Darcy Davis, and Nitesh V. Chawla. "Scaling and contextualizing personalized healthcare: A case study of disease prediction algorithm integration." Journal of biomedical informatics (2015).
- Feldman, Keith, Louis Faust, Xian Wu, Chao Huang, and Nitesh V. Chawla. “Beyond Volume: The Impact of Complex Healthcare Data on the Machine Learning Pipeline”. Towards Integrative Machine Learning and Knowledge Extraction. LNCS (2017).
- Feldman, Keith, Reid A. Johnson, and Nitesh V. Chawla. “The State of Data In Healthcare: Path towards standardization.” Journal of Healthcare Informatics Research (2018).
